Каждый день мы раздаем лицензионные программы БЕСПЛАТНО!

Giveaway of the day — Text-R Professional 1.100
Text-R Professional 1.100 был доступен бесплатно 11 сентября 2020 г.

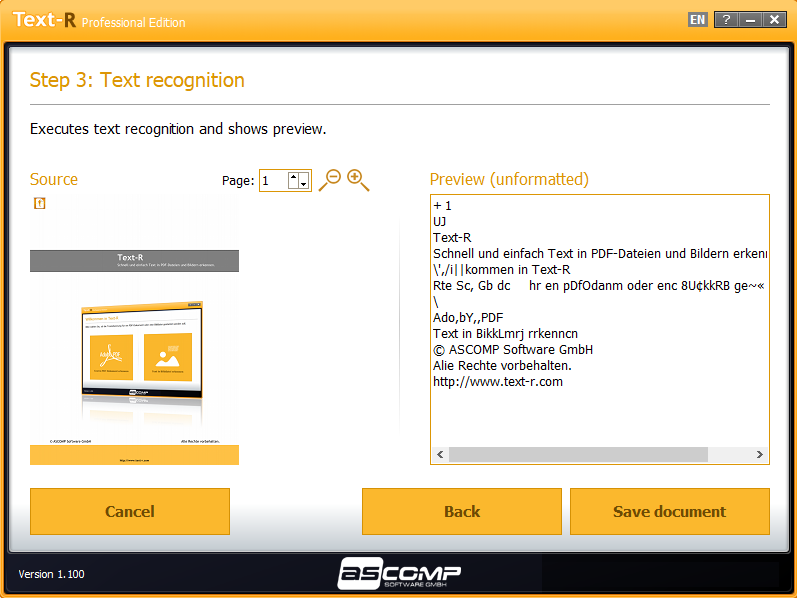
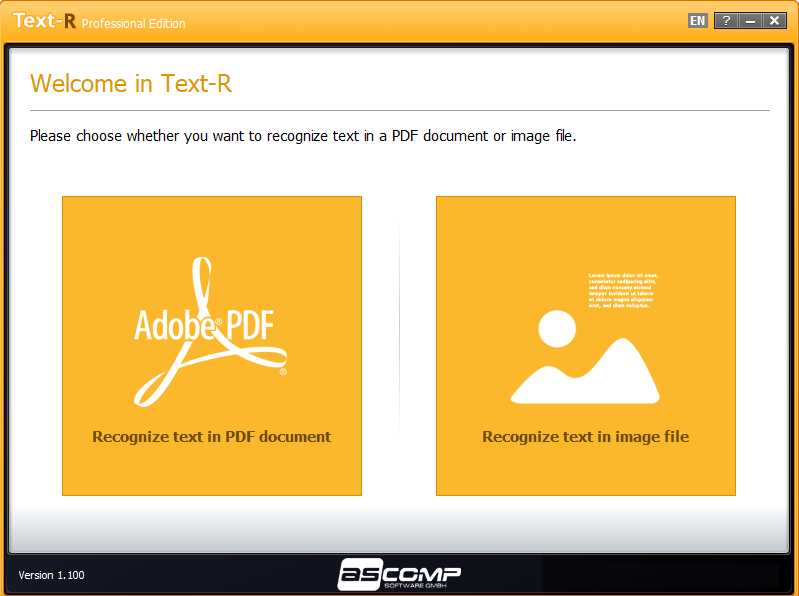

Проблема: файлы PDF и изображения из отсканированного бумажного документа содержат текст, который нельзя скопировать или отредактировать. Перепечатывать вручную тоже невозможно из-за размера документа и большого количества времени.
Решение: Text-R! Программа распознает текст в PDF-файлах и изображениях и позволяет их редактировать без особых навыков. Текст может быть сохранен в новом редактируемом документе PDF или RTF (Word). Форматирование остается близким к оригиналу, поэтому в большинстве случаев дополнительная обработка не требуется.
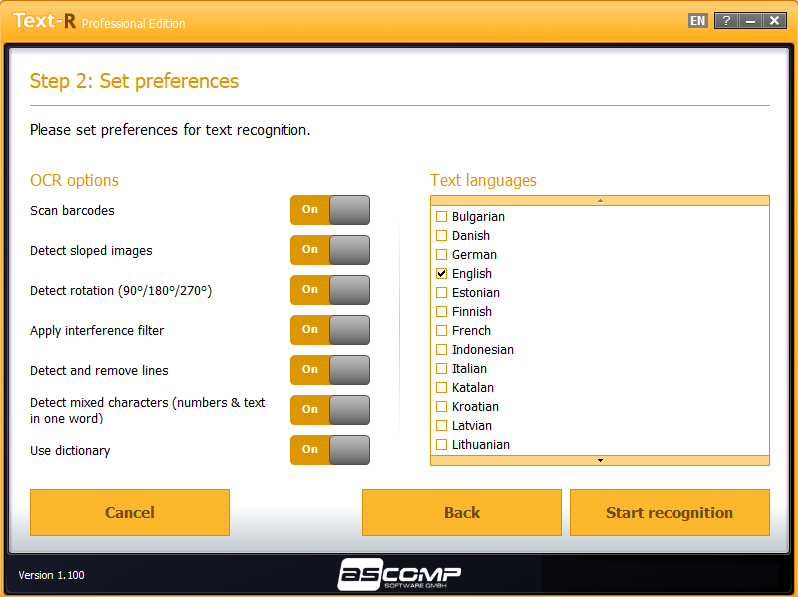
Встроенные словари и профессиональные фильтры OCR обеспечивают высокую точность распознавания текста. Таким образом, могут быть обнаружены искаженные фрагменты текста и элементы с иным направлением.
Пожалуйста, обратите внимание: бесплатная раздача содержит только текстовый файл со ссылкой для регистрации, пользовательский файл установки будет доступен после регистрации лицензии.
Системные требования:
Windows XP/ Vista/ 7/ 8/ 8.1/ 10 (x32/x64)
Разработчик:
ASCOMP Software GmbHОфициальный сайт:
http://www.ascomp.de/en/products/show/product/textr/tab/details/?design=redesign2019Размер файла:
0.59 MB
Licence details:
annual
Цена:
$33.90
GIVEAWAY download basket
Комментарии
Понравилась программа? Оставьте комментарий!
Q1: Is the OCR done on the local machine or is it client-server, or some hybrid?
Q2: Who's OCR engine do you use? (Aabby, Google, Other)
Q3: What are the performance stats or comparison on the OCR

Spam Sorenson,
The same version (1.100) of this was offered 6 months ago on March 12 -- your questions are answered there among the comments (see #27), although I did not notice any "performance stats" mentioned:
https://www.giveawayoftheday.com/text-r-professional-1-100/
Also, since I installed it then (and won't bother to replace it today), apparently some of my own observations have not yet been addressed (comment #30).
Installed with no problems. It has a small fixed size window, difficult to read, especially white text on yellow background. But the real problem is that the text must be sharp and clear in the original pdf. I tried some originals scanned on a Canon scanner and this is one line that was converted with my quote marks added here: "Gtatommt T)m0· Fchnmrv 1 ?(])1) thrcmah Fohrnaru )Q :mm J ' GP J ' " The original was printed text, and I can easily read it, but the program could not. Here is the original that I am manually typing in for this comment: "Statement Date: February 1, 2020 through February 29, 2020" Considerable manual correction would be needed. Other pages were better converted, but all had problems so every letter/character needs to be verified, and this is typical of any OCR software I already use, but most allow verification and correction inside the program.
I downloaded this program when it was up before
It does work for about 75% it does actually convert pdf/text pictures to TEXT
I suggest you convert to PLAIN TEXT, converting to DOC file only about 65% accurate.
My rating 7.5 out of 10
First of all, if it matters to anybody, these are the same people that put out Synchredible, the best file Synchronizer on the market.
That being said....
I have a special folder in which I keep some really awful PDF files to test out the grandiose claims of OCR converter software. Text-R bit the dust just like everyone else's program. The converted page was just full of garbage.
Now.....if ASCOMP is interested, I would gladly send my test PDF to them to play with. I just need an address where to send it.
Ничего не пишут про числа. ABBYYFineReader распознаёт цифры, но перегонять в числа надо ручками в экселе.
Save | Cancel
Единственная программа, которая распознала "без заморочек" текст в фотофайле. Но... на славянских языках - коряво, хотя неплохо на англ.
Save | Cancel